Empowering Product Innovation
Angel Esquembre, Data Scientist, and Christopher Bronner, Lead Machine Learning Scientist, share insights about Gecko—The Knot Worldwide’s custom-built experimentation platform.

By: Angel Esquembre and Christopher Bronner
At The Knot Worldwide, our vision is to ensure everyone around the world is empowered to create celebrations that are authentic to them for the moments that matter most. But, how do we ensure our features and functionalities truly meet the needs of our users? This is where data becomes the ultimate wedding guest—providing invaluable insights to guide our product development.
Data alone isn’t enough. We need to use the right statistical methodologies to draw valid conclusions from our data. That’s why we’re excited to introduce Gecko, our very own in-house experimentation platform. Built using open-source tools, Gecko empowers us to conduct A/B tests with scientific rigor at scale. This platform allows us to compare different versions of our product features and measure their impact on user behavior.
Why do we do A/B tests?
At The Knot Worldwide, we don’t guess what our couples need. Instead, we use data to guide every step of our product development process. We’re constantly evolving and improving the platform to create a seamless and joyful wedding planning experience.
We could just release our changes and look for sudden spikes, week-over-week increases, and call it a day. However, in a complex environment—with several teams trying to move the same needle, seasonality, marketing campaigns, and other external factors—attributing any change in the relevant metrics to specific product improvements cannot be achieved through simple pre-post comparison. That’s where A/B testing comes into play.

A/B testing is widely regarded as the “gold standard” for measuring the impact of changes in a product. This method involves comparing two or more variants of the product by splitting the audience and exposing each group to a different variant. This method provides a controlled way to isolate the effects of specific changes, ensuring that any differences in outcomes are directly attributable to the variations being tested.
While conducting randomized experiments is highly effective, it does come with certain prerequisites and challenges. Achieving statistically significant results requires a sufficient volume of traffic, and creating and managing A/B tests requires additional resources, both of which may not always be feasible for all organizations.
The Knot Worldwide’s experimentation journey
Our journey with experimentation started with basic ad-hoc scripts for each experiment. This wasn’t ideal because each team was using different criteria to set up tests and interpret the results. As we tested more and more, we set up some processes and conventions that helped us gain in standardization. On the bad side, each experiment setup required a lot of effort from our data scientists. The code used to analyze the data was hard to maintain and duplicated for each experiment. This also means more bugs. At some point, this became a bottleneck for scaling our experimentation program.
We explored third-party alternatives and worked with a third-party experimentation platform for a while. This was great for reducing the amount of work involved in setting up each experiment, to the point where product managers were able to set up their experiment dashboards. However, it didn’t match our needs perfectly for a few reasons. For example, our criteria for stopping and evaluating experiments differed from those of the third-party provider, and this confused our product managers. This also meant we lacked control over which statistical methods were used.
As the number of experiments each quarter continued to grow, we needed a tailored solution that would allow us to match our development speed. We decided to build our very own experimentation platform that would fit our needs.
This allows us to maintain standardization with reduced effort, allowing Product managers to build their dashboards while maintaining statistical accuracy, based on our criteria. Speed, standardization and customization are the keys to the success of our proprietary tool.
Introducing Gecko: The Knot Worldwide’s Custom-Built Experimentation Platform

The back-end, powered by gecko-core
We built our own back-end system for a couple of reasons: it is easier to maintain, and it can be accessed from any source. This is the most important piece of the platform.
Gecko-core handles mainly two things: the communication with our database—fetch, create and update data—and the statistical calculations.
We needed to make it easy for users to select entry points and metrics for our experiments. With thousands of different data sources, our model helps simplify the complexity of our data. They are organized into four types of models:
- Entry point models contain instances where users meet a certain set of entrance criteria (whether or not they were bucketed).
- Assignment models contain instances of users being bucketed in an experiment (assigned to a variant). They are essentially a combination of entry points and variant information.
- Fact models serve as the foundation for metrics. For example, one fact model could contain checkout events with order value for each event which could be used for a metric like “conversion to order” but also another metric “average order value”.
- Entity Property models contain static attributes of users which never change for a given user.
Each model follows strict conventions that allow us to build some logic on top of them. These standards, while simple, are incredibly powerful. They include guidelines for naming our models, the entities, the date at which the action happens, and the model itself.
These models are built by the data scientists based on the needs that arise.
Each experiment is represented by a record in our EXPERIMENTS table. We store the dashboard configuration that the user entered while creating the experiment dashboard on the front-end, as well as the calculated results. An Airflow DAG – a job set up in the cloud that runs scheduled jobs – manages the daily update of the experiment results in this table.
The front-end, powered by Streamlit
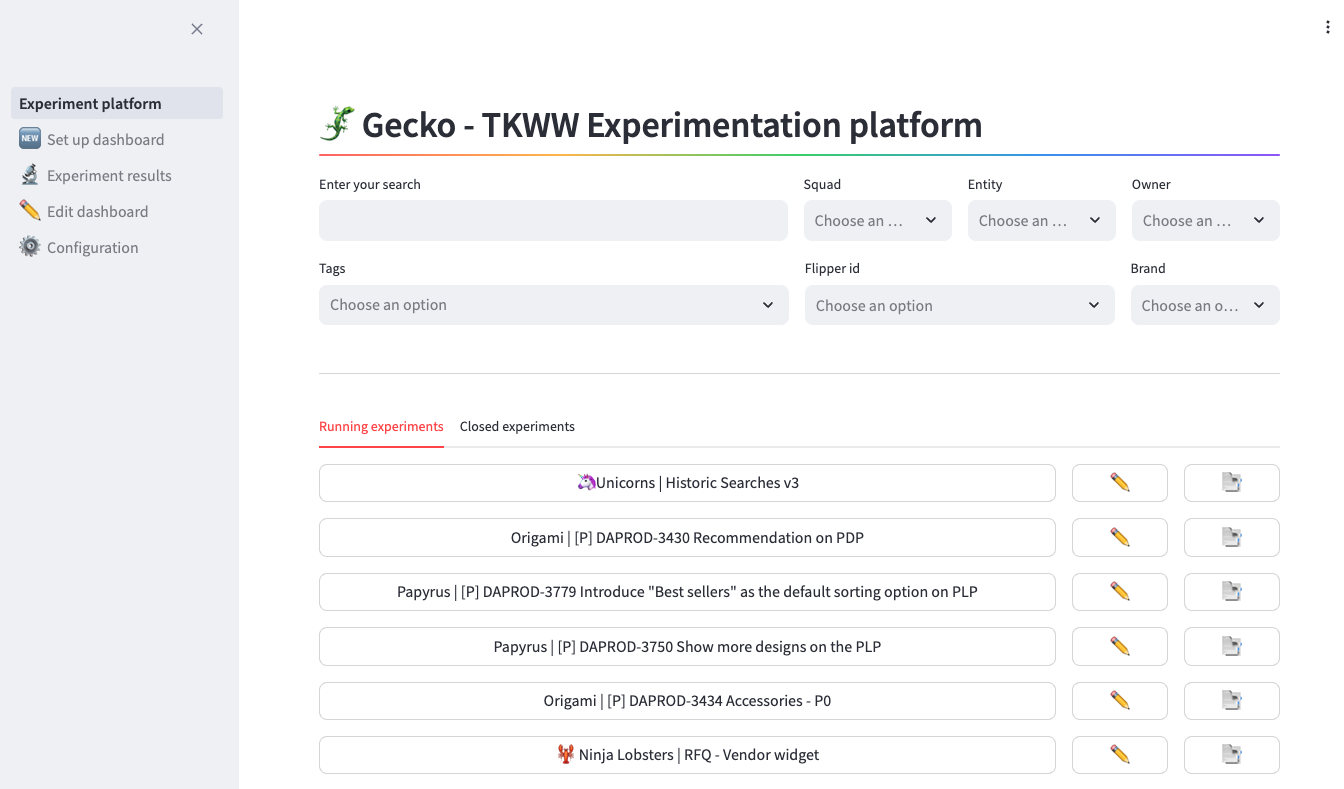
The front-end is built as a Streamit app, an open-source Python framework to deliver dynamic data apps with only a few lines of code. It allows our stakeholders to build experiment dashboards with just a few clicks.
It leverages the back-end to create, edit, close, or delete experiment dashboards, and populate experiment results. We have built a fully functional app, with the feedback from our product managers, that allows them to easily:
- Create a dashboard with just a few clicks and simple UX.
- Edit their dashboards to add/delete metrics as they need.
- See their experiment results with a verbose interpretation of the statistical metrics based on our very own stopping criteria – more on this in the statistical section.
- Explore some useful information: interactive charts that show the historical evolution of the lift or the daily and cumulative traffic, technical specs like the queries that run in the background, and some sanity checks such as population balance.
- Close their dashboard and select which variant has won.
- Delete/duplicate their experiment dashboards.
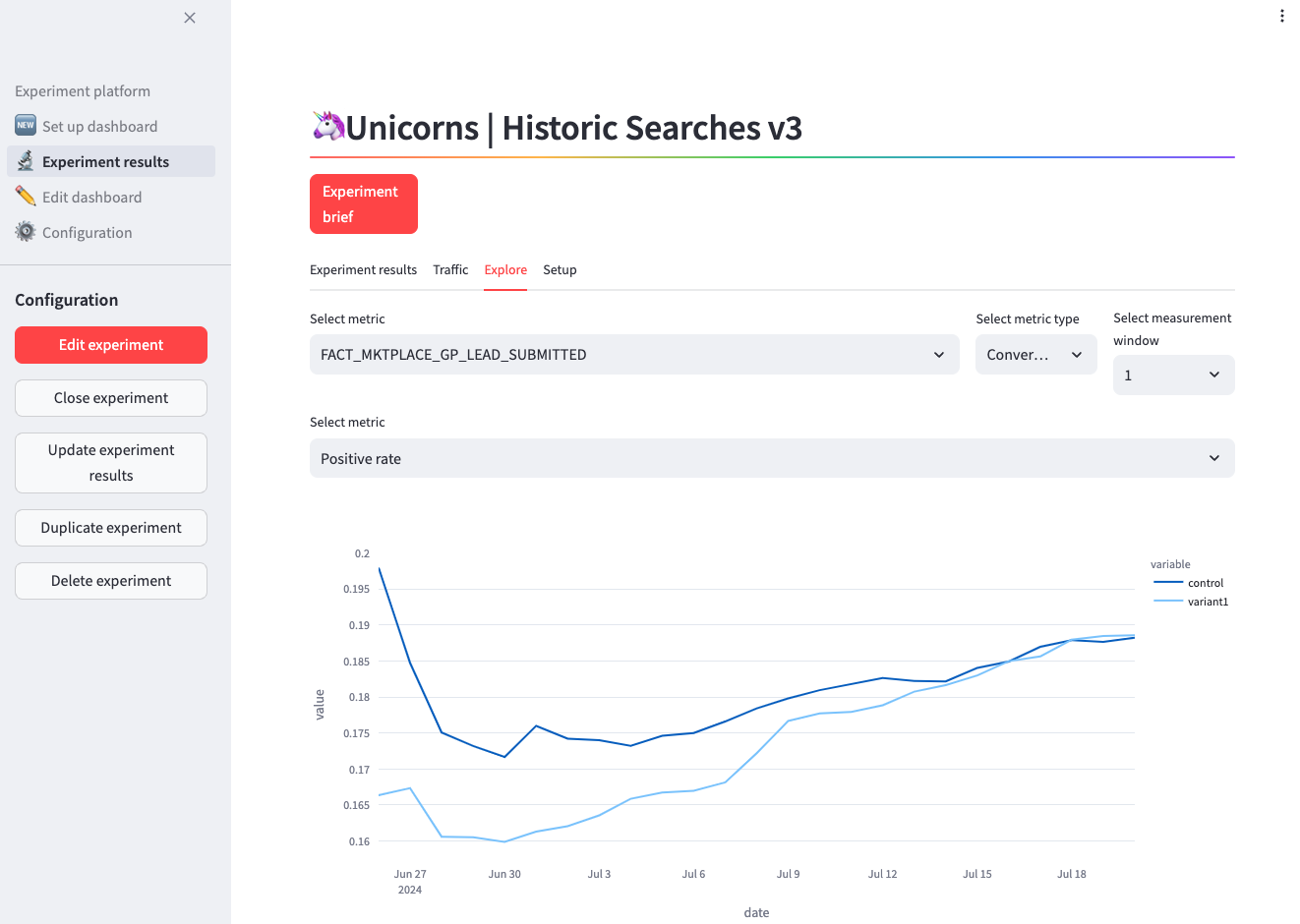
Benefits of this approach
When building in-house solutions, there are typically both pros and cons. For us, the pros largely outweigh the cons, and here are some of the reasons:
- Control over the statistical methodology: There is plenty of literature out there on what are the best methodologies to run statistical tests. With our implementation, we have control over which one we use, and we can update it as needed.
- Independence to implement new features: We can devote as many resources as we want to the improvement of the platform. We do not depend on an external party’s roadmap to deploy new functionalities.
Statistical Analysis with Bayesian Approach
Given the raw results of an experiment, we need to determine whether any observed change in a metric between the control and variant group is due to an impact of our product change on user behavior, or whether it’s merely due to noise. This is a crucial step to be able to decide whether or not to roll out a new feature.
To distinguish a signal of changed user behavior from noise, we employ a Bayesian approach which is implemented in a separate Python module. Unlike frequentist significance tests, this method allows us to not only make the binary decision whether or not the results are statistically significant but also to make robust statements on the magnitude of the change. In addition, in the Bayesian framework, we don’t need to run an experiment until we reach a predetermined sample size, but we can monitor results starting immediately after a test is launched and stop the test as soon as we have enough data (which may take a shorter amount of time when a variation has a large impact).
Instead of calculating a p-value with a hypothesis test at the end of a fixed time window, we continuously monitor three Bayesian measures for each metric in our experiment:
- The expected loss of each variant: this is a measure of the risk associated with rolling out a particular variant. It quantifies the drop that can be expected if we choose to roll out a variant but we chose wrong. Intuitively, this gives a sense of the “worst case” scenario, something that we can’t quantify in a frequentist framework.
- The probability to be best of each variant: this metric quantifies the probability that a particular variant performs better than any other variant in the test.
- The credible interval: similar to a confidence interval, this gives a lower and an upper bound for the lift or drop of a metric between the variant in question and a baseline control group.
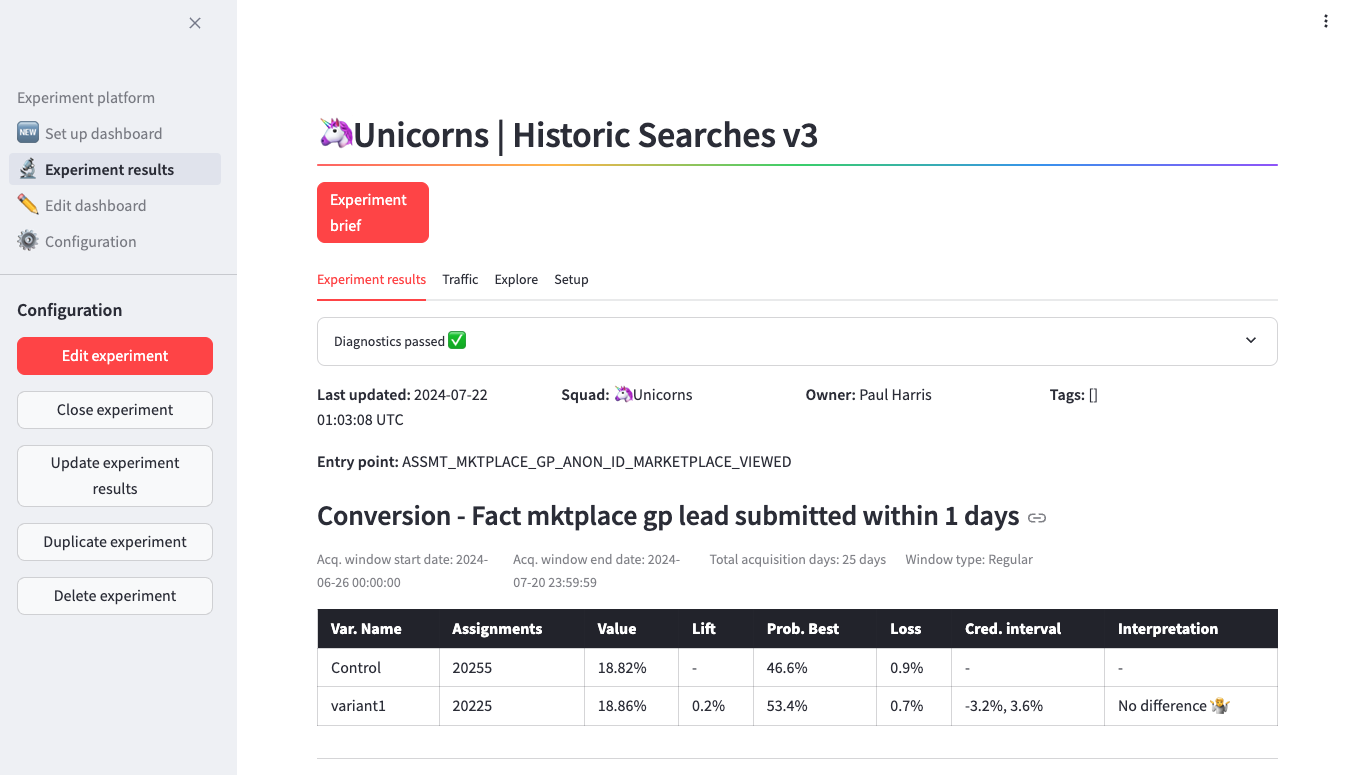
We use these metrics in combination to decide whether enough data is available to stop an experiment and declare one variant the winning one. To avoid this decision to be influenced by biases of team members who have a vested interest in the outcome of the test, we solely rely on quantitative stopping criteria and only end a test if
- the test duration exceeds a minimum of 2 weeks,
- the expected loss of a variant is below a certain percentage threshold (typically 1%)
- and the probability to be best exceeds a certain threshold (80%)
In Gecko-core, we use an open source Python package called bayesian_testing to calculate the Bayesian metrics based on the raw results and apply our stopping criteria to the result. We implement this through a wrapper around different bayesian_testing classes for different underlying distributions (e.g. Bernoulli distributions for conversion tests or normal distributions for tests of means) which provides expected loss and probability to be best. We then calculate the credible interval as the interval between the 5th and 95th percentile of the posterior distribution from that package.
For cases where the underlying distribution doesn’t align with any of our defined distributions, we use our bootstrapping implementation to calculate the test results.
The output of our Bayesian analysis module consists of the three Bayesian metrics as well as an unambiguous rollout decision based on the stopping criteria, such as “Variant wins”, “Control wins,” or “Need more data.” Being able to generate these actionable conclusions from the raw data enables data scientists and stakeholders to interpret the outcome of a test without any room for subjective judgment.
Conclusion
In conclusion, the development and implementation of Gecko, The Knot Worldwide’s in-house experimentation platform, has been instrumental in advancing our ability to innovate and meet the evolving needs of our users. By leveraging a tailored solution that aligns perfectly with our unique requirements, we have gained unprecedented control over the statistical methodologies used in our A/B testing processes, enabling us to make data-driven decisions with confidence. This level of customization and standardization across teams has not only streamlined our experimentation efforts but also ensured that our product enhancements are both meaningful and effective for our diverse user base.
Looking ahead, Gecko will continue to play a crucial role in our product development strategy, empowering teams to quickly adapt and refine their approaches based on real-time data insights. The integration of Bayesian analysis further strengthens our ability to discern true user behavior changes from statistical noise, allowing for more nuanced and informed decision-making. As we continue to scale and evolve our platform, Gecko will remain at the forefront of our commitment to delivering a seamless and joyful experience for all who use our products.